AI crawlers need to be more respectful

Photo by Zanyar Ibrahim on Unsplash
In the last few months, we have noticed an increase in abusive site crawling, mainly from AI products and services. These products are recklessly crawling many sites across the web, and we’ve already had to block several sources of abusive traffic. It feels like a new AI gold rush, and in their haste, some of these crawlers are behaving in a way that harms the sites they depend on.
At Read the Docs, we host documentation for many projects and are generally bot friendly, but the behavior of AI crawlers is currently causing us problems. We have noticed AI crawlers aggressively pulling content, seemingly without basic checks against abuse. Bots repeatedly download large files hundreds of times daily, partially from bugs in their crawlers, with traffic coming from many IP addresses without rate or bandwidth limiting.
AI crawlers are acting in a way that is not respectful to the sites they are crawling, and that is going to cause a backlash against AI crawlers in general. As a community-supported site without a large budget, AI crawlers have cost us a significant amount of money in bandwidth charges, and caused us to spend a large amount of time dealing with abuse.
AI crawler abuse
We have been seeing a number of bad crawlers over the past few months, but here are a couple illustrative examples of the abuse we’re seeing:
73 TB in May 2024 from one crawler
One crawler downloaded 73 TB of zipped HTML files in May 2024, with almost 10 TB in a single day. This cost us over $5,000 in bandwidth charges, and we had to block the crawler. We emailed this company, reporting a bug in their crawler, and we’re working with them on reimbursing us for the costs.
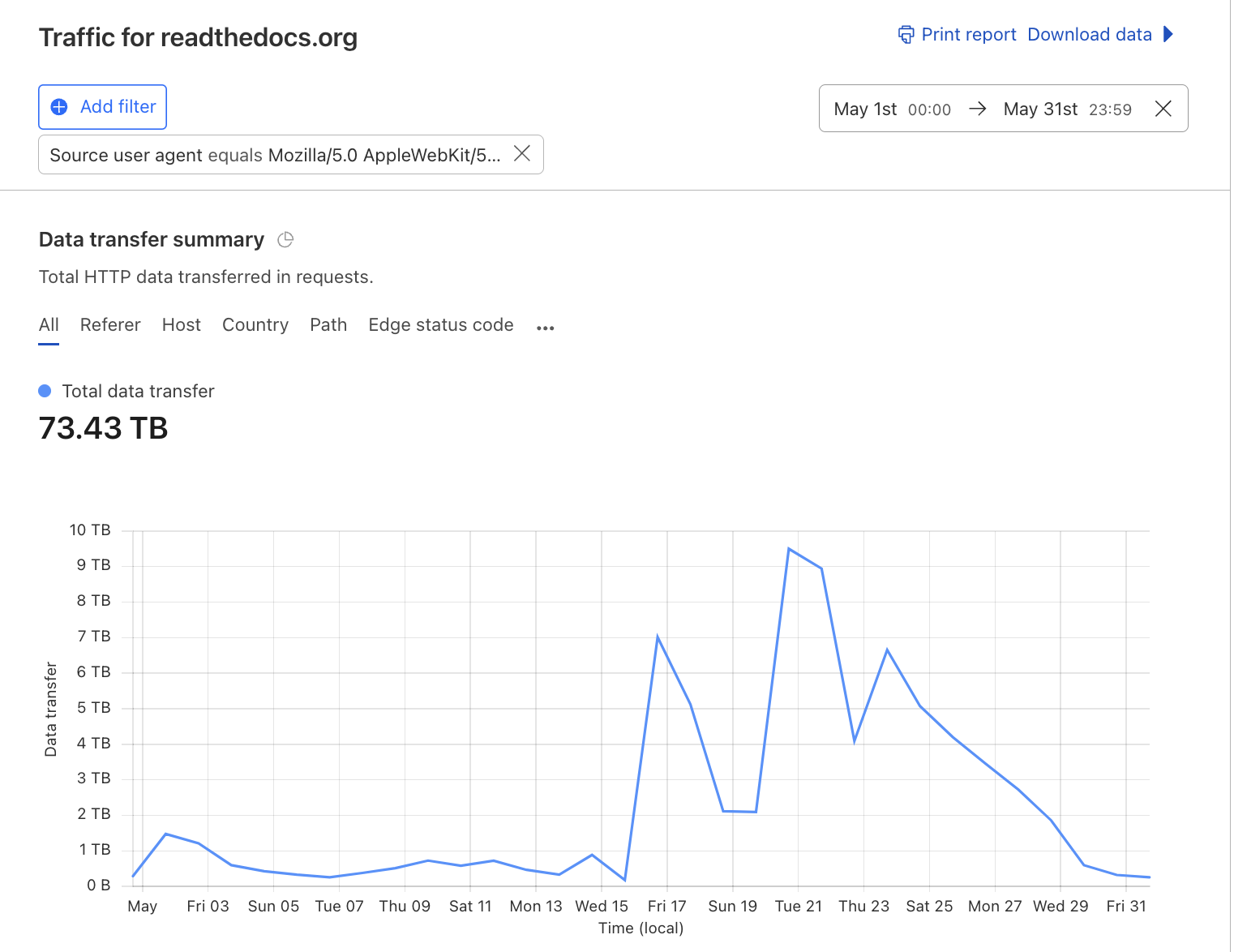
This was a bug in their crawler that was causing it to download the same files over and over again. There was no bandwidth limiting in place, or support for Etags and Last-Modified headers which would have allowed the crawler to only download files that had changed. We have reported this issue to them, and hopefully the issue will be fixed.
We do have a CDN for these files, but this request was for an old URL that had an old redirect in place. This redirect went to an old dashboard download URL, where we don’t have CDN caching in place for security reasons around serving other dynamic content. We are planning to fix this redirect to point to the cached URL.
Example web requests
10 TB in June 2024 from another
In June 2024, someone used Facebook’s content downloader to download 10 TB of data, mostly Zipped HTML and PDF files. We tried to email Facebook about it with the contact information listed in the bot’s user agent, but the email bounced.
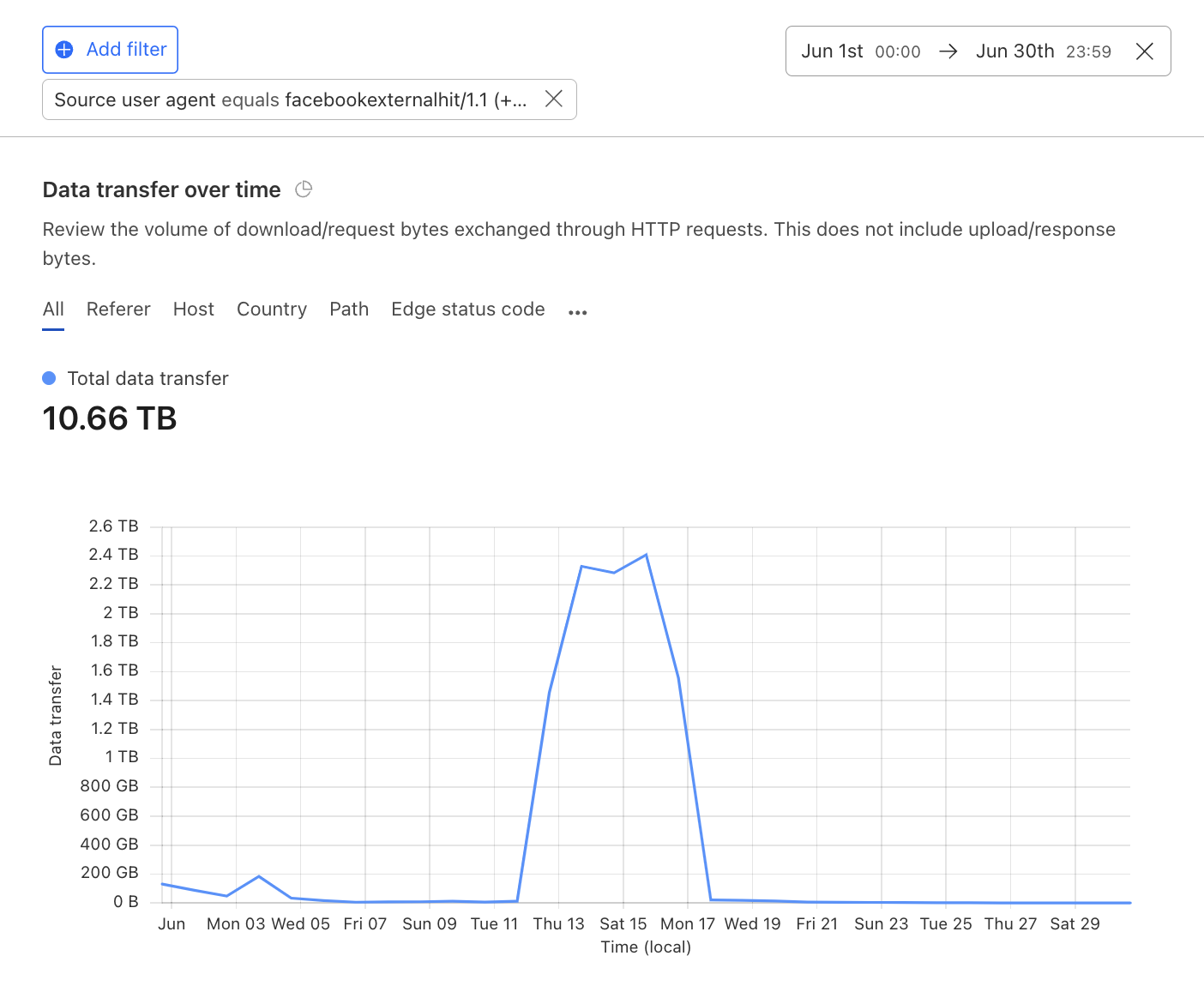
We think this was someone using Facebook’s content downloader to download all of our files, but we aren’t really sure. It could also be Meta crawling sites with their latest AI project, but the user agent is not clear.
Actions taken
We have IP-based rate limiting in place for many of our endpoints, however these crawlers are coming from a large number of IP addresses, so our rate limiting is not effective.
These crawlers are using real user agents that identify them, which is a good thing. However, we can’t simply rate limit all user agents to our platform because many real users use the same browsers with the same user agent. (CDN providers: if you’re reading this, there’s an opportunity here!)
We have taken a few actions to try to mitigate this abuse:
- We have temporarily blocked all traffic from bots Cloudflare identifies as AI Crawlers, while we figure out how to deal with this.
- We have started monitoring our bandwidth usage more closely and are working on more aggressive rate limiting rules.
- We will reconfigure our CDN to better cache these files, reducing the load on our origin servers.
Outcomes
Given that our Community site is only for hosting open source projects, AWS and Cloudflare do give us sponsored plans, but we only have a limited number of credits each year. The additional bandwidth costs AI crawlers are currently causing will likely mean we will run out of AWS credits early.
By blocking these crawlers, bandwidth for our downloaded files has decreased by 75% (~800GB/day to ~200GB/day). If all this traffic hit our origin servers, it would cost around $50/day, or $1,500/month, along with the increased load on our servers.
Normal traffic gets cached by our CDN, and doesn’t cost us anything for bandwidth. But because many of these files are not downloaded often (and they’re large), the cache is usually expired and the requests hit our origin servers directly, causing substantial bandwidth charges. Zipped documentation was designed for offline consumption by users, not for crawlers.
Next steps
We are asking all AI companies to be more respectful of the sites they are crawling. They are risking many sites blocking them for abuse, irrespective of the other copyright and moral issues that are at play in the industry.
As a major host of open source documentation, we’d love to work with these companies on a deal to crawl our site respectfully. We could build an integration that would alert them to content changes, and download the files that have changed. However, none of these companies have reached out to us, except in response to abuse reports.
We also ask that they implement basic checks in their crawlers for all sites. A good example is the RFC2616Policy downloader from Scrapy, which implement many of these policies.
If these companies wish to be good actors in the space, they need to start acting like it, instead of burning bridges with folks in the community.